Researchers from CWI’s Human-Centered Data Analytics group and VU University examined four widely used datasets: the general knowledge base Wikidata, the Art & Architecture thesaurus (or AAT) from The Getty Institute for describing cultural heritage objects, and two lexical databases for English (Princeton WordNet) and Dutch (Open Dutch WordNet). Except the last one, these datasets are available as linked open data (LOD).
Controversial terms about people and cultures in widely used datasets
Outdated, stereotypical, and potentially offensive words often appear in openly available datasets, CWI researchers have found. These datasets power many applications (such as online dictionaries) and machine learning algorithms, creating risks of further cultural stereotype propagation.
Publication date
15 February 2024
Share this page
What is LOD?
Linked Open Data allows interlinking multiple datasets using unique resource identifiers (or URIs). For example, Wikidata's resource "immigrant" with the ID "Q12547146" is linked to the resource "immigrants" with the ID "294916520" from the African Studies Thesaurus developed by Leiden University. URIs keep links stable even if the names ("immigrant") of resources change or even if these names are in different languages. It also allows machines to parse links between different resources. The idea of LOD is that everyone can reuse datasets freely and add new links.
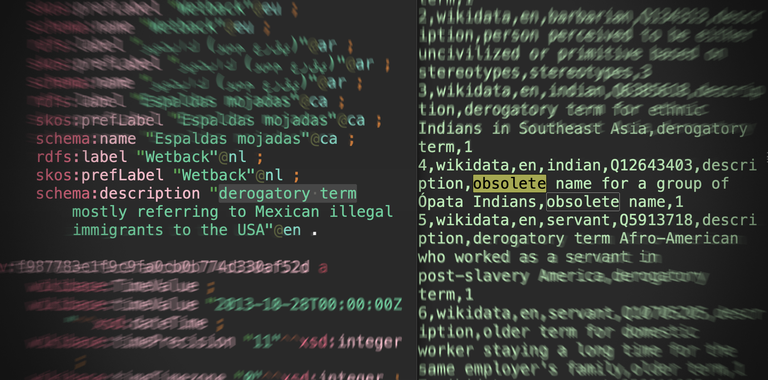
To enable humans to read the data (and display it in interfaces), the developers of LOD describe resources with text (also known as literals). Words used in these literals are not always neutral, CWI researchers explain in a paper to be published in the Proceedings of The ACM Web Conference 2024 (manuscript is available on arXiv). “When outdated and culturally stereotyping terminology is used in literals, they may appear as offensive to users in interfaces and propagate stereotypes to algorithms trained on them”, the authors write.
Still frequently used
For this reason they examined how frequently English and Dutch controversial terms occur in LOD and in what kind of descriptions: literals can be used as main names of resources or serve as longer descriptions explaining their meaning. The terms researchers investigated were categorized as contentious by experts from the cultural heritage field. These terms are frequently used in museum databases and refer, for example, to historically marginalized peoples, colonial territories and traditions.
The researchers concluded that potentially offensive terms – such as ‘coolie’, ‘coloured’, ‘hottentot’, ‘Mongoloid’, ‘mulatto’, ‘Negro’, ‘transvestite’ – are still frequently used in the textual descriptions of data that are usually displayed in interfaces and used for indexing. "We have also found various cases of how data contributors attempt to mark certain terms in literals, for example, by stating that a term is ‘offensive’. But these markers are rarely used and if they are used, they are used inconsistently. Moreover, there is no guarantee that these markers of offensiveness will be acknowledged when the datasets are reused”, author Andrei Nesterov from CWI says. “With our empirical results we highlighted the scale of the problem. Our insights can also help in designing more systematic approaches to address the spread of stereotypes via LOD.”
Examples
Stereotyping language can be spread from one dataset to another, Nesterov explains. "Open Dutch WordNet, although not available as LOD, is a part of another lexical database – Dutch Open Multilingual WordNet – and, in its turn, it is used as a part of the even larger online dictionary BabelNet. We found evidence of offensive terms from the original Open Dutch WordNet ending up in BabelNet.” For example, BabelNet provides derogatory synonyms of the Dutch term ‘homoseksualiteit’ (homosexuality) taken from Open Dutch WordNet without any explanation or marking." These synonyms include insulting terms like ‘flikker’(‘faggot’) and ‘geïnverteerde’ (‘inverted’).
‘How contentious terms about people and cultures are used in Linked Open Data’, Andrei Nesterov (CWI), Laura Hollink (CWI), Jacco van Ossenbruggen (VU).