Keeping the navigation structure of a large, frequently-changing website up-to-date can be a daunting task. This paper describes a website for a large online publication, and the method used to ensure that the navigation structure is kept up-to-date, by using the widely available make program, and files that represent the site's navigation structure.
Website design; Website management; Unix tools
In 1995, the Special Interest Group for Computer-Human Interaction of the ACM, SIGCHI [1], decided to put its member publication, the SIGCHI Bulletin [2], online in HTML. This is a publication that comes out quarterly in issues of about 100 pages; it was decided to publish the paper and HTML versions simultaneously each quarter.
Because SIGCHI represents computer-human interaction, it was important that the site reflect the group's aims, and be as usable as possible. It is well known that electronic publications are harder to read than paper ones [3], but there are also obvious advantages to having publications online. So the first question was how to make an online publication as readable as possible. To try and answer this we went through a design phase where we designed the navigation structure for the site (see [4]) to support both serial reading as well as browsing. We then created a pilot version of three issues which we user tested, before going live.
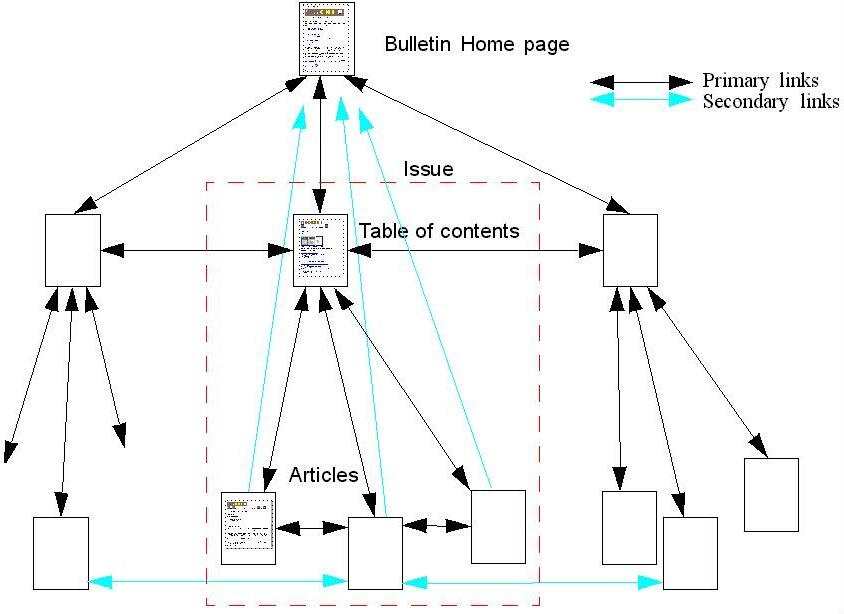
The structure of the site is shown in figure 1. Apart from standard base material (such as colophon, editorial staff, submission process, and so on, the site consists of a series of issues. Each issue consists of a series of articles. Each article is a single HTML document (amongst other reasons to aid printing and searching).
Figure 1: The structure of the site
However, apart from this simple, shallow, hierarchical structure, supported with navigational links up and down the tree, there is a layer of links (partially shown in turquoise in the figure) linking issues together, linking articles in an issue together, and linking related articles across issues together. Furthermore there are 'slices' of the site, giving collections of related articles from all issues, such as all columns on Education.
The site is a static one: there is no dynamically generated content, just issues added regularly, though there can be extra updates if an additional article is added from earlier (pre-online) issues, or due to corrections.
Material for an issue is submitted electronically, usually by FTP, in a multitude of different formats. Luckily, the paper version of the Bulletin is produced with Adobe FrameMaker, which has a large number of import filters. These are then combined using the FrameMaker book facility, printed on a typesetter, and sent off to the printers.
It is at this point that the production of the Web version is started. The first step is to use Frame2HTML [5] to convert the files to HTML Documents. Although Frame2HTML has the ability to process FrameMaker Book files, we didn't use that feature, since it produces a navigation hierarchy different to the one we wanted. Consequently we just processed each article separately.
Frame2HTML produces fairly rough-and-ready HTML, so we had to create a number of filters, mostly written in sed[6], to fix up the HTML, and to convert URLs and mail addresses in the text to clickable versions in the HTML (which Frame2HTML doesn't do). See figure 2 for an example of a sed expression to do such a conversion. We had hoped to be able to use HTMLTidy[10] to correct the HTML, but unfortunately Tidy was not designed to be used in a pipeline, and failed in several cases, requiring manual intervention.
Styling was done with a simple link to a CSS stylesheet [7] (with the exception of a single BGCOLOR attribute on the BODY element). In the early days of the online Bulletin, this was radical stuff, but CSS is designed so that websites that use it are still visible on non-CSS browsers, so we weren't worried about the low number of browsers that supported CSS then. Log files now show that more than 95% of surfers are using a CSS-empowered browser.
s/[a-zA-Z0-9][a-zA-Z0-9+\\._\\/\\-]*@[a-zA-Z0-9\\._\\-]*[a-zA-Z0-9]/<A HREF="mailto:&">&<\/A>/g
Figure 2: A sed expression for making email addresses clickable
These processes leave us with a directory full of files of reasonable-quality HTML, to which the navigation links have to be added, and the whole then needs to be linked into the rest of the Bulletin website. Since the production work is done on a separate machine from the server, the whole site was then FTP'd in its entirety to the server.
The pilot three issues were all assembled by hand, and we had an immediate taste of the problems of making sure that articles and issues are properly linked into the Online Bulletin hierarchy. It was easy to make a mistake and link to the wrong place, and checking that links were correct was time-consuming and also error-prone.
Therefore one of our first actions before going live was to write a program that added the links and inserted a new issue into the hierarchy.
To make this possible all that had to be done by hand was create the top-level index.html page for any issue. The program that did the work was a Unix shell script that took this index.html file, and from it determined the names of the files in the issue, and the order that they occurred in. Using shell variables of the names of the previous and next files, a new HTML file could be generated using the contents of the HTML file for the article, with the necessary links.
This process is sketched in Figure 3: the filenames are generated to a file called files (using fairly simple grep and sed commands), and these are taken one by one, setting the variables this, next and prev, representing the filenames of the file being processed, and the previous and next files in the issue. The command process then takes these three filenames and creates a file with the necessary navigation added.
generate-filenames <index.html >files
this=""
for next in `cat files` ""
do
case $this in
"") # skip first time round
*)
process "$this" "$prev" "$next" > results/$this
esac
prev=$this
this=$next
done
Figure 3: The file processing loop
Articles on the same subject in each issue typically have the same file name (for instance education.html for the Education column) and so it is easy to link between these: the process command can look to see if there is a file with the same name in the previous and next issues, and add it to the navigation for the file. However, files that do not share names, or span greater distances than two issues (for instance if someone writes an article, and someone else writes a response a few issues later) need to be treated specially. For this there is a central file (also created by hand) that records these relationships. This file just contains names of files in the form "file1: file2", meaning that file1 is a previous link for file2 (and file2 is a next link for file1). Two simple greps by the process command then reveal if the file currently being processed has such extra links.
Note though that adding a new Education Column in this issue means that not only must this issue's article link to last issue's, but the last issue also needs to be updated to point forward to this issue, and that the existence of the file that specifies extra relationships in general can additionally mean a change to any issue. An upshot of this is that we had to reprocess all issues every time we added a new issue, in order to ensure that all links were correct, and then transfer the whole website to the server. In the beginning this was perfectly satisfactory, but after a year or two the site started getting so big that processing time and transfer time started to get out of hand. It was at this point that we looked for optimisations in the process of adding an issue.
One thing we quickly realised when searching for a solution was that when adding a new article to an issue or a whole new issue to the site the file times of the new files would be newer than the existing ones, which suggested we might be able to use make which deals with just such relationships.
Make [8] can be seen as a primitive form of constraint satisfier: given a number of invariants between files, and commands that can restore the invariant between them, it works out and executes a chain of commands to restore the invariants.
The invariants are very simple: they just specify (unidirectional) dependencies between files, and using the time stamps of those files, make determines if a file that depends on another file is older than that file, and if so, which actions need to be executed to restore the invariant.
The invariants are given in a so-called makefile. This file typically contains specifications such as
prog: prog.h prog.c
cc -o prog prog.c
This says that the file prog depends on the files prog.h and prog.c. If either prog.h or prog.c are newer than the file prog (i.e. they have been changed since prog was last changed), or prog doesn't exist at all, then the command "cc �o prog prog.c" gets executed to create or recreate prog.
The challenge for us was to find a way of specifying the dependencies between files, and the commands for restoring the dependencies.
Firstly it was clear that we needed to have both source files (the raw HTML produced by Frame2HTML) as well as processed files (the website files) existing independently. Then it would be possible to see that a source file had changed and therefore that the corresponding web file needed updating. In other words for a file in the issue called 2001.3:
web/2001.3/file.html: source/2001.3/file.html
process source/2001.3/file.html > web/2001.3/file.html
That was the easy part. However, if you have a situation of two documents, A and C, both linked to each other, and you want to add B between them, you have to update A and C as well. Note that A, B and C don't depend on each other in the make sense: if B gets changed, A and C don't need to change, it is only if a new file gets inserted that A and C need to be reprocessed.
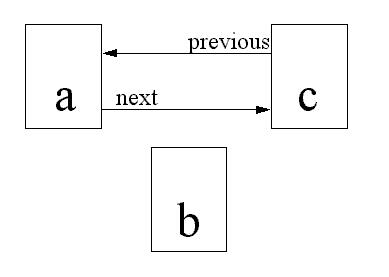
Figure 4: Initial state of a and c before adding b
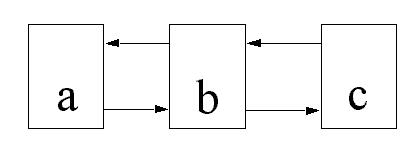
Figure 5: State after adding b
Unfortunately, make doesn't have the ability to treat the creation of a file as a special case: its rules treat updating a file identically to creating it. Since it is changes in the navigation structure rather than changes in documents that are needed to trigger updates, we needed a way of representing the navigation structure in files that could be used in the Makefiles.
So the rule we needed to represent for each file was along the lines of:
web/2001.3/file.html: source/2001.3/file.html source/2001.3/file.links
process source/2001.3/file.html > web/2001.3/file.html
(Actually, the makefiles are in the source directory, so the actual rules are:
web/200-1.3/file.html: file.html file.links
process file.html > web/2001.3/file.html
)
The file file.links has to contain a representation of the required linking structure for the HTML file; this can be generated automatically with a command that resembles the file processing command in figure 3 above.
The original form we chose for the file was a simple listing of the linking relationships. Here is an example for the education article education.html for the 1998.3 issue:
previous article: chairs.html
next article: vid.html
article in previous issue: 1998.2/education.html
article in next issue: 1998.4/education.html
So if this file changes, we know that the navigation structure for the file it represents has changed and can be used to trigger a reprocessing of the file.
However, we soon realised that we needed all the values in this file when reprocessing the HTML file it described, so we quickly dual-purposed the file, by making it a shell file that set some shell variables that could then be used:
prev=chairs;previ=1998.2/education;next=vid;nexti=1998.4/education
Then the 'process' line of the makefile rule could use this file as well to pass on the values of the variables:
web/1998.3/education.html: education.html education.links
process education.html education.links > web/1998.3/education.html
The links file clearly depends on the index.html file for the current issue, since if index.html changes then so would a number of these link files; therefore you might be tempted to say:
education.links: index.html
makelinksfile index.html > education.links
However, if the index.html file changes, some but not all of the links files need to be updated, and it would be overkill to recreate all of them (since this would trigger reprocessing of all files). So we created an additional file for each issue, called Navigation, that depends on the index.html file. The command used for updating it would then recreate the necessary individual links files:
Navigation: index.html
checklinks index.html
The command checklinks runs through index.html, in a similar fashion to the processing loop illustrated in figure 3, creating for each file mentioned there a candidate links file, which it then compares with the one that is already there, and if it is different, overwriting the old one. In this way changes in the navigation structure cause reprocessing only of the affected HTML files and benign changes in the index.html file, such as the addition of a comment, don't trigger any reprocessing at all.
If any of the individual links files get overwritten, then the main Navigation file also gets overwritten by checklinks to record that fact. This file, called a touch file in make terminology, doesn't contain any useful information, but is only used to trigger make dependencies by being overwritten by any suitable piece of information (for instance the date).
The above actions only deal with the navigation structure for links within an issue. However, as the above example links file shows, articles also link to articles in other issues. What this means is that if the navigation structure for an issue changes, it may have an effect on other issues. This is reflected by changing the make rule for the Navigation file:
Navigation: index.html ../1998.2/Navigation ../1998.4/Navigation
checklinks index.html
This says that if the navigation structure for a linked issue changes, then the navigation structure for this issue gets checked for changes.
Above (in the section The Problem) we also mentioned an extra file that specifies relationships between files that do not share names, or span greater distances than two issues. This also gets dealt with by checklinks; and so this file must also be in the list of dependency files for the Navigation file:
Navigation: index.html ../1998.2/Navigation ../1998.4/Navigation ../Special
checklinks index.html
The last piece in the puzzle is the process for creating the Makefiles, which must be created automatically. Since the makefile for an issue contains rules like:
web/2001.3/chairs.html: chairs.html chairs.links
process chairs.html chairs.links > web/2001.3/chairs.html
it clearly depends on the index.html file for the issue. So there is a
simple makefile that creates the issue-dependent makefile, and then causes
that to be used:
all: issue-makefile targets
issue-makefile: index.html
createmakefile index.html > issue-makefile
targets:
make -f issue-makefile Navigation
make -f issue-makefile files
The first rule is a special one. Since the file 'all' doesn't exist, the rules for 'issue-makefile' and 'targets' are executed. Since the rule for 'all' has no further actions, nothing more happens, so this is just a way to ensure that the other rules get executed.
The first of these two other rules ensures that the issue-makefile gets (re)created if necessary, and the second (which again uses a non-existent file name to ensure it gets executed) calls make recursively twice with the newly-created issue-dependent makefile to ensure that the Navigation rule gets executed as well as the rules for all of the individual files.
After a couple of years of experience with this system, we repurposed it for a similar type of site, the online proceedings of a conference, CHI 97[9]. Although this has a different structure to an online periodical, it does have a similar hierarchy consisting of several classes of submissions (Papers, Posters, Tutorials, etc) which each consist of a number of papers. Again we wanted to support linear reading as well as browsing, so we used a similar navigation structure. Although the site no longer regularly gets updated (except for corrections), using the method described meant we could put the site up piecemeal as the submissions came in, and didn't have to worry about updating the navigation links. The only change we had to make to our system was to the email address processing code: we discovered that many authors used the form "{john, anne, peter}@place.com" to represent their email addresses.
If we had had to process each issue of our website by hand and keep checking the navigation structure of our website as it grew, we would have gone crazy. The insight on how to represent the navigation structure as a series of files which were amenable to processing by make saved us the trouble of having to write much special-purpose software, and saved a lot of processing time. The fact that make is also widely available for free meant that our solution was also low-cost.
[1] ACM Special Interest Group in Computer-Human Interaction, http://www.acm.org/sigchi/
[2] The SIGCHI Bulletin, ACM, New York, http://www.acm.org/sigchi/bulletin/
[3] J.D. Gould et al., Why Reading is Slower from CRT Displays than from
Paper, Proc. CHI+GI '87, ACM Press, 1987.
[4] Steven Pemberton, Hot Links and Cool Sites: How Do You Make an Electronic
Journal Readable?, CWI Quarterly, Volume 8(1995) no. 4,
315-328, http://www.cwi.nl/cwi/publications_bibl/QUARTERLY/Pemberton/elec-bulletin.fm.html
[5] Jon Stephenson von Tetzchner , Frame2HTML, http://www.w3.org/Tools/fm2html.html
[6] Lee E. McMahon, SED &ndash A Non-interactive Text Editor, Bell Labs,
1979
[7] CSS, http://www.w3.org/Style/CSS
[8] S.J. Feldman, Make – A Program for Maintaining Computer Programs,
Bell Labs, 1979
[9] Steven Pemberton (ed.), Proceedings of CHI 97, http://www.acm.org/sigchi/chi97/proceedings/
[10] Dave Raggett, HTML Tidy, http://www.w3.org/People/Raggett/tidy/
Steven Pemberton is a researcher at the CWI, a nationally-funded research centre for Mathematics and Computer Science in the Netherlands, the first non-military Internet site in Europe. His research interests are in software architectures to support the user. He has been involved with the Web from the early days, organising two workshops at the first WWW conference, and being involved with the CSS and HTML Working Groups of W3C. He is editor-in-chief of ACM/interactions, a publication on user interfaces, and is now chair of W3C's HTML Working Group.
Steven Pemberton
CWI
Kruislaan 413
1098 SJ Amsterdam
The Netherlands