
"This is clearly a submission that needs to be shredded, burned, and the ashes buried in multiple locations"
"I think the audience will eat him alive. But I want to be there to hear it."
A generic method for injecting any parsable structured document into the XML pipeline, and treat it as XML.
It is based on the observation that, looked at in the right way, an XML document is no more than the parse tree of some external form.
Your input might be
body {color: blue; font-weight: bold}
and your XML processor would see
<css>
<rule>
<selector>body</selector>
<block>
<property name="color" value="blue"/>
<property name="font-weight" value="bold"/>
</block>
</rule>
</css>
Your input might be
a×(3+b)
and your XML processor would see
<expression>
<product>
<letter>a</letter>
<sum>
<digit>3</digit>
<letter>b</letter>
</sum>
</product>
</expression>
Your input might be
http://www.w3.org/TR/1999/xhtml.html
and your XML processor would see
<uri>
<scheme>http</scheme>
<authority>
<host>
<sub>www</sub>
<sub>w3</sub>
<sub>org</sub>
</host>
</authority>
<path>
<seg>TR</seg>
<seg>1999</seg>
<seg>xhtml.html</seg>
</path>
</uri>
Your input might be
{a=0;}
and your XML processor would see
<program>
<statement>
<assignment>
<variable>
<identifier>a</identifier>
</variable>
<expression>
<number>0</number>
</expression>
</assignment>
</statement>
</program>
Let's take a suitable grammar for expressions:
expr: term; sum; diff.
sum: expr, "+", term.
diff: expr, "-", term.
term: factor; prod; div.
prod: term, "×", factor.
div: term, "÷", factor.
factor: letter; digit; "(", expr, ")".
letter: ["a"-"z"].
digit: ["0"-"9"].
expr
|
term
|
prod
-----+------
| | |
term "×" factor
| |
factor ----+-----
| | | |
letter "(" expr ")"
| |
"a" sum
-----+----
| | |
expr "+" term
| |
term factor
| |
factor letter
| |
digit "b"
|
"3"
expr
| term
| | prod
| | | term
| | | | factor
| | | | | letter
| | | | | | "a"
| | | "×"
| | | factor
| | | | "("
| | | | expr
| | | | | sum
| | | | | | expr
| | | | | | | term
| | | | | | | | factor
| | | | | | | | | digit
| | | | | | | | | | "3"
| | | | | | "+"
| | | | | | term
| | | | | | | factor
| | | | | | | | letter
| | | | | | | | | "b"
| | | | ")"
<expr>
<term>
<prod>
<term>
<factor>
<letter>a</letter>
</factor>
</term>
×
<factor>
(
<expr>
<sum>
<expr>
<term>
<factor>
<digit>3</digit>
</factor>
</term>
</expr>
+
<term>
<factor>
<letter>b</letter>
</factor>
</term>
</sum>
</expr>
)
</factor>
</prod>
</term>
</expr>
expression: ^expr.
expr: term; ^sum; ^diff.
sum: expr, "+", term.
diff: expr, "-", term.
term: factor; ^prod; ^div.
prod: term, "×", factor.
div: term, "÷", factor.
factor: ^letter; ^digit; "(", expr, ")".
letter: ^["a"-"z"].
digit: ^["0"-"9"].
<expr>
<prod>
<letter>a</letter>
<sum>
<digit>3</digit>
<letter>b</letter>
</sum>
</prod>
</expr>
Parsing
One of the most popular parsing methods is LL1.
This is a deterministic parsing method: just looking at the next symbol in the input you know what is coming next.
This makes it very fast: O(n).
In other words, if the input string is twice as long, then parsing takes twice as long.
program: block.
block: "{", statements, "}".
statements: statement, ";", statements; empty.
statement: if statement; while statement; assignment; call; block.
if statement: "if", condition, "then", statement, else-option.
else-option: "else", statement; empty.
empty: .
while statement: "while", condition, "do", statement.
assignment: variable, "=", expression.
variable: identifier.
call: identifier, "(", parameters, ")".
...
This grammar is not LL1 because of this:
statement: if statement; while statement; assignment; call; block.
assignment: variable, "=", expression.
variable: identifier.
call: identifier, "(", parameters, ")".
So if the next symbol is an identifer, you don't know which alternative to use.
We can rearrange the grammar:
statement: if statement; while statement; assignment-or-call; block.
assignment-or-call: identifier, tail.
tail: assignment-tail; call-tail.
assignment-tail: "=", expression.
call-tail: "(", parameters, ")".
Apart from its speed, another reason that LL1 is so popular is that it is easy to convert a LL1 grammar directly into code.
program: block.
procedure program = { block; }
block: "{", statements, "}".
procedure block = { expect("{"); statements; expect("}")}
statements: statement, ";", statements; empty.
procedure statements = {
if nextsym in statement-starters
then {
statement;
expect(";");
statements;
} else {}
}
statement: if statement; while statement; assignment-or-call; block.
procedure statement = {
if nextsym="if" then ifstatement;
else if nextsym="while" then whilestatement;
else if nextsym=identifier then assignment-or-call;
else if nextsym="{" then block;
else error("syntax error");
}
But it is also possible to "interpret" the grammar, rather than generate code from it:
procedure parserule(alts) = {
if (some alt in alts has nextsym in starters(alt)) then parsealt(alt);
else if (some alt in alts has (empty(alt)) then {}
else error("syntax error");
}
procedure parsealt(alt) = {
for term in alt do {
if nonterminal(term) then parserule(definition(term));
else expectsym(term);
}
}
Declarative: where you say what you want, but not how to achieve it.
A grammar can be seen as a sort of declarative programming language for parsers.
Can only parse restricted languages.
Requires skill and experience to write the grammar.
Can parse any sort of language -- no restrictions.
People are put off by the worst-case parsing time of O(n³): if the input is twice as long, parsing takes 8 times longer.
HOWEVER, this is a function of the language, not of the method: if the language is LL1, then Earley is O(n) -- just as efficient as deterministic parsing!
People find Earley hard to understand, but that is because it is always described in terms of its (procedural) implementation, rather than its (declarative) intent.
Today, I hope to fix that.
Earley is an interpreter for grammars.
As should be clear from the above, if you have a rule like
block: "{", statements, "}".
then parsing can just steam ahead, and that it is only when you have choice points that you have to decide which to take:
statement: if statement; while statement; assignment; call; block.
And that's where Earley gets clever.
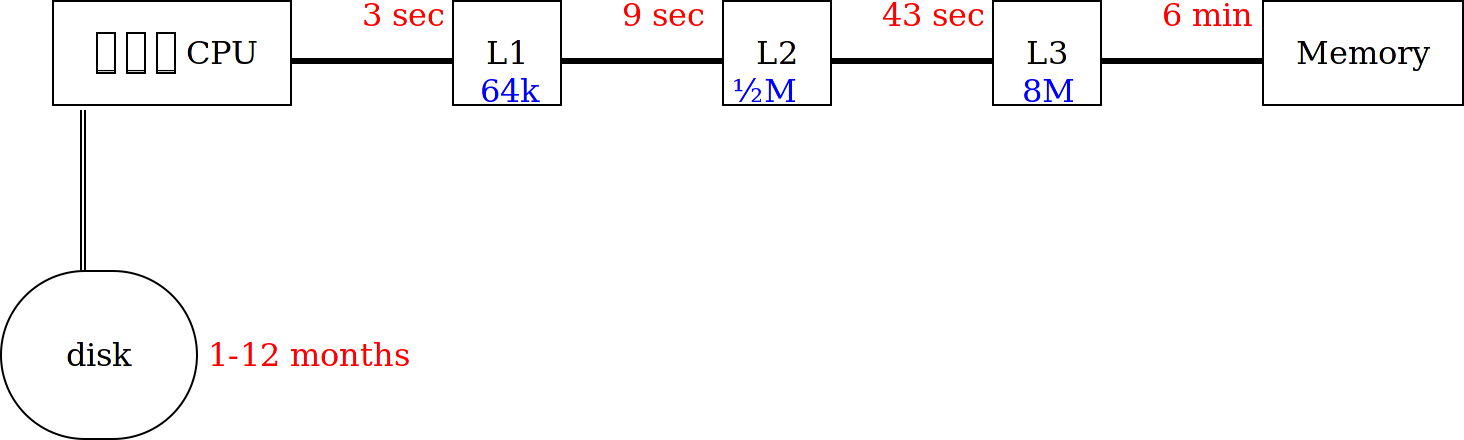
A current desktop computer has a clockspeed of 3GHz.
In other words: a computer's clock ticks as many times PER SECOND as a regular clock does during a person's life (a long life).
So how can we understand what 3GHz really means?
Let's slow the computer right down.
A computer CPU and its registers, running at 1Hz.
Still very fast: it can multiply 2 eighteen-digit numbers together in one second!
But at some point, it has to get data from the memory.
Want to guess how long that takes?
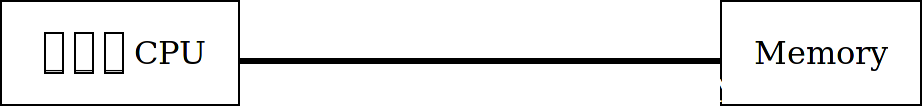
But at some point, it has to get data from the memory.
Want to guess how long that takes it?
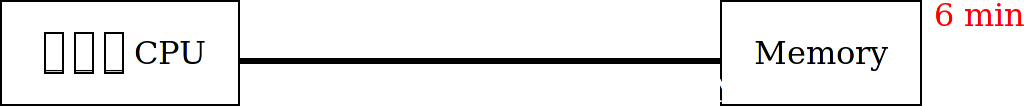
Much of the complexity of modern computers is in dealing with this bottleneck, with parallel instruction decoding, and data streaming.
And caches.
Each cache is smaller, quicker, and much more expensive than the next.
Note that each cache is about 10× larger than the previous.

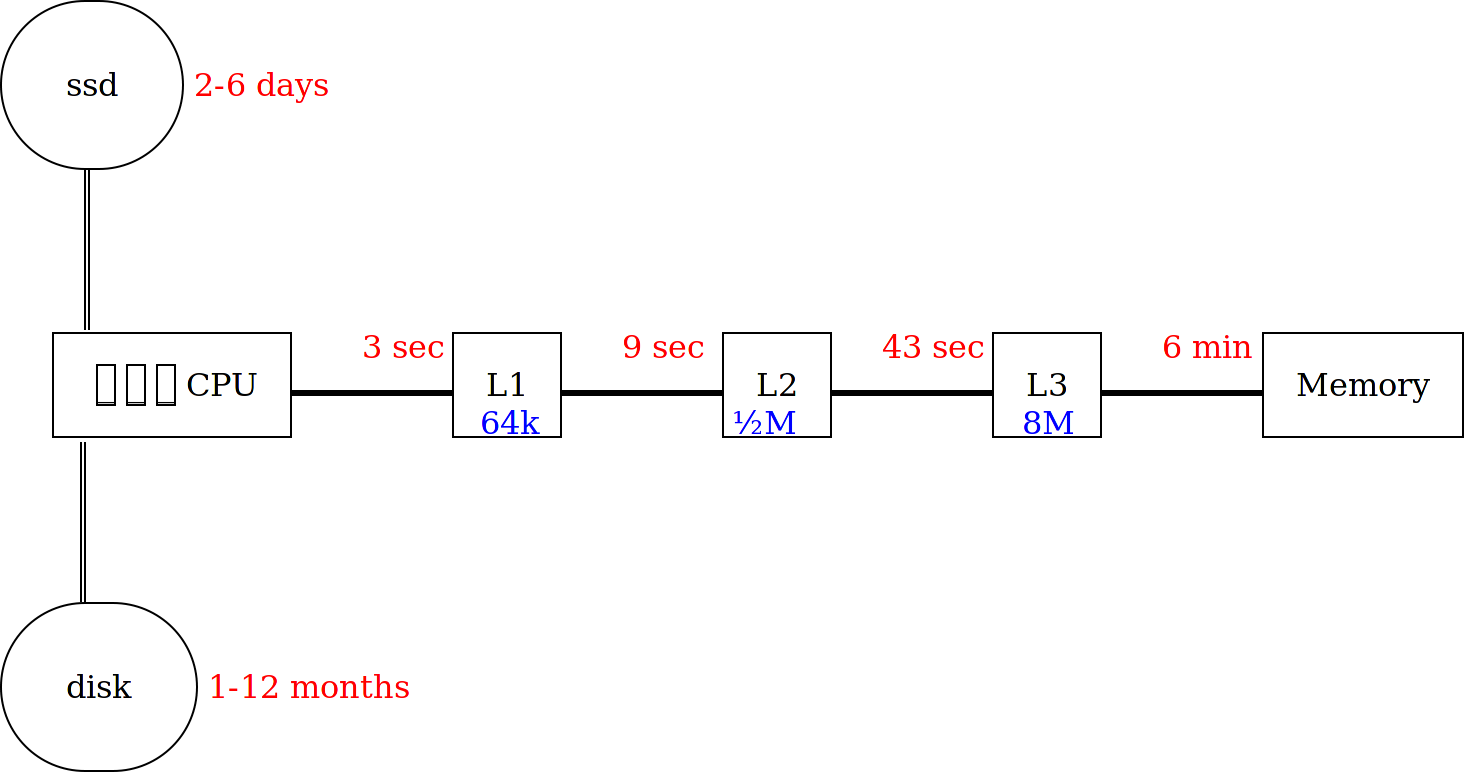
But at some point, the program has to talk to a disk.
Want to guess again how long that takes?
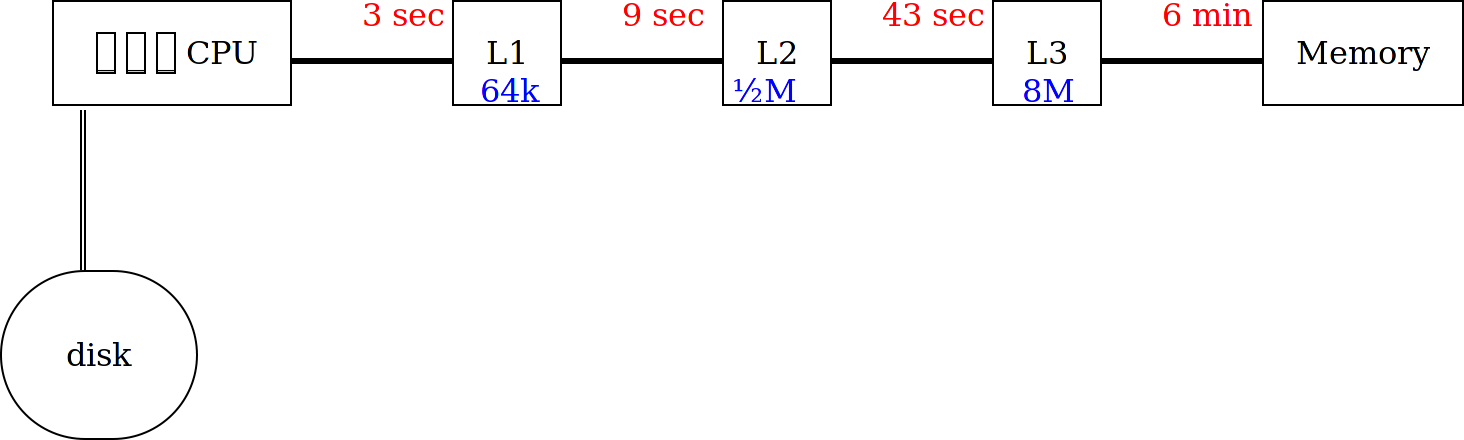
But at some point, the program has to talk to a disk.
Want to guess again how long that takes?
This difference is one of the reasons it really is worth forking out for an SSD.
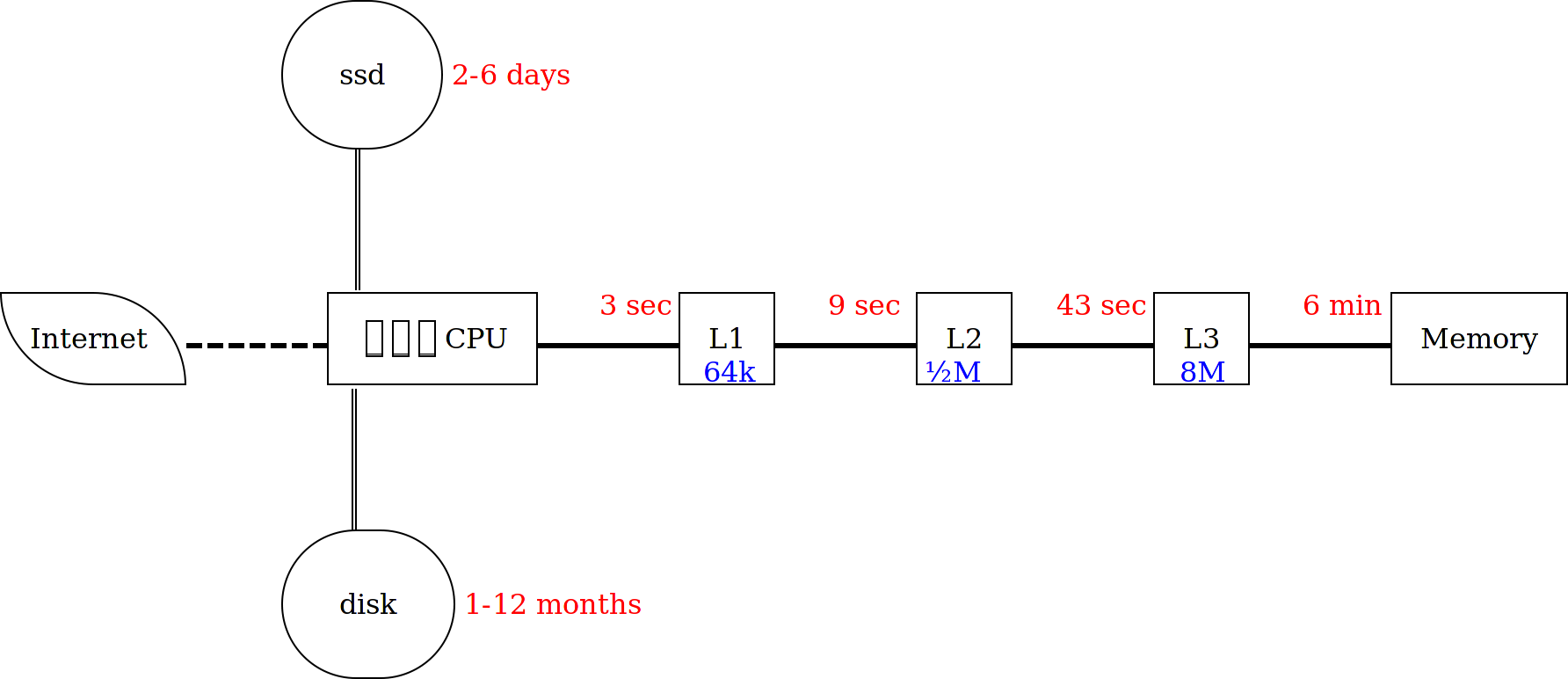
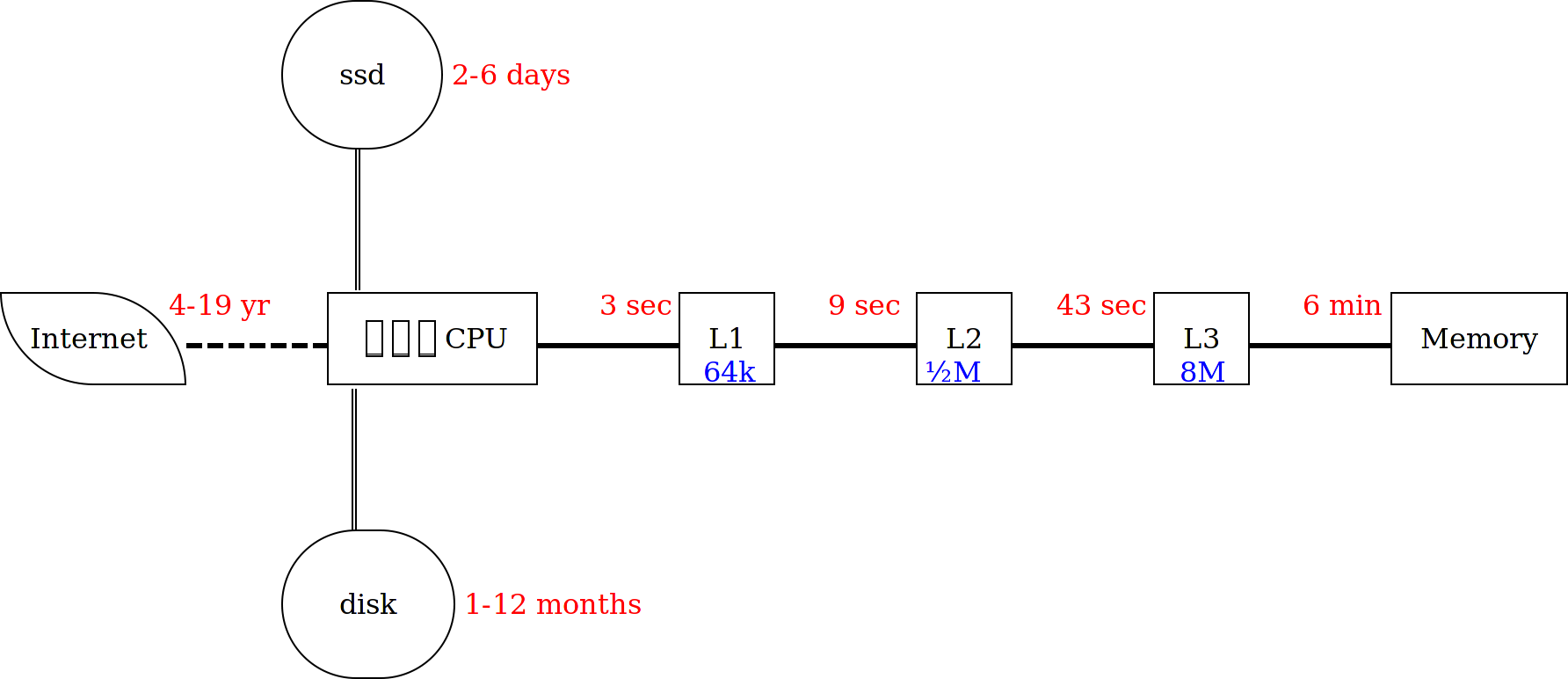
More complex hardware cannot overcome these --huge-- delays, so the solution is in software:
Many programs (hundreds) are loaded in memory together, and given (short) time slots.
Short in human terms that is. (A year or two in 1Hz units)
When a program gets a time slot it runs until:
Then the program is paused, and added to a list of programs waiting to be run.
These can be ordered on the basis of priority.
A new program is selected from the lists and give the next time slot.
This gives the impression of many programs running in parallel.
This is how Earley works: using pseudo parallelism.
When it comes to a branch, it runs all the options rather than making a choice.
When a rule has to be run, like
statement: if statement; while statement; assignment; call; block.
then the (in this case five) alternatives are all added to a queue of tasks waiting to be run.
The tasks are ordered on their position in the input (so tasks earlier in the input get run first).
A task when run gets to do exactly one thing:
If a task is started at a position in the input where the same task is already running or queued, a new copy is not created, but the existing one is linked to.
This is partly optimising: the same task doesn't get run twice.
But also essential: it prevents infinite recursion.
Here is the input:
{a=0;}
We are now going to parse this with Earley.
The initial task is queued, and immediately run (» is the 'program counter', and shows where in the task we are):
program@0: » block.
This causes block to be queued.
program@0: » block.
block@0: » "{", statements, "}".
Block now matches a single symbol, recording at which
position:
block@0 : "{"@1, » statements, "}"
Block is still the only active task, so it causes
statements to be queued. Statements has two
alternatives, so two tasks get started:
statements@1: » statement, ";", statements. statements@1: » empty.
So statement gets run, which causes 5 tasks to be added.
statement@1: » if statement. statement@1: » while statement. statement@1: » assignment. statement@1: » call. statement@1: » block.
Three of these fail immediately because their initial symbol doesn't match the next symbol in the input (if, while, and {).
This leaves assignment and call.
assignment@1: » identifier, "=", expression.
call@1: » identifier, "(", parameters, ")".
Assignment gets run, and starts task
identifier.
Call similarly gets run, and wants to start
identifier, but that has already been started at this position, so
it doesn't start a new one.
Identifier succeeds, and returns to both parents, both of which
are re-queued:
assignment@1: identifier@2, » "=", expression.
call@1: identifier@2, » "(", parameters, ")".
Call fails to match against "(", and so dies.
Assignment matches "=", and continues, at this point being the
only active task.
assignment @1: identifier@2, "="@3, » expression.
Expression gets called, and eventually returns successfully,
having matched the "0".
assignment@1: identifier@2, "="@3, expression@4 ».
So assignment returns successfully, and requeues its parent,
statement.
statement@1: assignment@4 ».
Which having now succeeded, returns to its parent:
statements@1: statement@4, » ";", statements.
This successfully matches ";"
statements@1: statement@4, ";"@5, » statements.
This causes statements to be called again, at position 5, and
it succeeds with the 'empty' alternative.
statements@1: statement@4, ";"@5, statements@5 ».
So statements requeues its parent:
block@0 : "{"@1, statements@5, » "}".
This matches the closing brace:
block@0 : "{"@1, statements@5, "}"@6 ».
block requeues its parent
program@0: block@6 ».
And then there are no more tasks active, and we end.
The last step is creating the parse-tree of the successful parse.
This can be done by following back the trace of completed tasks.
Starting from the task for the program
program@0: block@6 ».
we can then find the task for block:
block@0 : "{"@1, statements@5, "}" @6 »
From there the task for statements:
statements@1: statement@4, ";"@5, statements@5 ».
And then for statement:
statement@1: assignment@4 ».
And then for assignment:
assignment@1: identifier@2, "="@3, expression@4 ».
and so on.
The code to do this is simple:
HOW TO SERIALISE name FROM start TO end:
IF SOME task IN trace[end] HAS
(symbol task = name AND finished task AND start.position task = start):
WRITE "<", name, ">"
CHILDREN
WRITE "</", name, ">"
CHILDREN:
PUT start IN newstart
FOR (sym, pos) IN done task:
SELECT:
terminal sym: WRITE sym
ELSE:
SERIALISE sym FROM newstart TO pos
PUT pos IN newstart
<program>
<block>{
<statements>
<statement>
<assignment>
<variable>
<identifier>a</identifier>
</variable>
=
<expression>
<number>0</number>
</expression>
</assignment>
</statement>;
<statements>
<empty></empty>
</statements>
</statements>
}</block>
</program>
Using the techniques described earlier, this can be reduced to
<program>
<statement>
<assignment>
<variable>
<identifier>a</identifier>
</variable>
<expression>
<number>0</number>
</expression>
</assignment>
</statement>
</program>
Earley has had a bad press for a long time, largely because of its worst-case results, which were no fault of its own.
In fact it is a simple and effective parsing algorithm that allows you to write your grammars without special knowledge.
(I now know of four ixml implementations. Please tell me if you implement it, and give me feedback!)