This is my one thousandth annual address to this noble institution!
(OK, 1000 to base 2, which is 8 in old-fashioned units).
The book is in progress...
I discussed why Facebook (and other websites with user-contributed content) are bad for the web.
I introduced RDFa as a new technology for making web pages machine-readable, and how that could be used to create a distributed social web. Now adopted by such notables as Best Buy, and the British Government.
Another technology that has adopted RDFa is ODF, the Office Document Format. This year was a turning point for ODF: at least two governments, The UK and NL, have decided to use ODF as its standard format instead of Microsoft Office.
I discussed how and why new technologies cause the death of incumbent companies.
I mentioned that Dixons had stopped selling film cameras. Now Kodak is gone.
I asked "Is Linux a Disruptive Technology?" and quoted "Linux will outship Windows on new PCs in 2009". That was before Microsoft created the cheap Windows 7 Starter, which delayed the rise of Linux.
Now more than half of current computing devices use Linux (and that's not counting wireless routers, satnav, internet radios...). Linux is now the leading computing platform.
I noted that each time computer prices dropped by a factor of ten, you got a new class of computers that got used in a different way.
1M: Mainframe
100K: Minicomputer
10K: Workstation
1K: PC
and that netbooks and tablets are the €100 computer, and I predicted the coming of a €10 computer.
Since then the first €10 computer, the Raspberry Pi arrived, which has about the same power as a €100 computer from 6 years earlier, or a €1000 computer from 10 years earlier.
Last year I said: Now we should be watching for the €1 computer. This year it arrived:
A phenotype is the result of the effect of genes+environment, including your body, character, etc. An extended phenotype is something controlled by genes, but not physically part of the body, such as a bird's nest.
This talk was about how computers can be considered part of our extended phenotype, and explained how it was our genes that ultimately produced them.
(At the time I thought that would be the only time I would ever give the talk, but since then I have been invited to give it several more times.)
There are objective realities, and subjective realities. I talked about the physical, psychological and social aspects of colour perception as a subjective reality, and how they relate to the objective reality of frequencies of light.
I compared the introduction of the internet with the introduction of the printing press, and pointed out the parallels, pointed out that were some ongoing processes, and where that may lead.
Ostensibly about copyright, this talk argued that just as telephone calls have become ever cheaper since the introduction of the internet, so will content become cheaper, since we no longer need the expensive infrastructures that are needed to support classical content like books and records, but that authors and other content creators will end up earning more (for exactly the same reason).
I also argued that record shops (and book shops) are dying not principally because people are now buying online, but (with examples from other fields as well) because what got people into record shops was the need for information, and that once people were in the shops, they would then buy. Now people get their information from other sources, they never need to enter the shops any more, and thus have stopped buying there.
A colleague-friend who used to live in Amsterdam, is gay, and has been away for several years, returned recently, and remarked that gay bars are disappearing.
So are there less gays? Of course not. My theory is that with the introduction of dating apps, the information role of gay bars has disappeared, and so gays have less need to go to those particular bars. They can just go to any bar now.
[Funnily enough, the day after I gave this talk, the local Amsterdam newspaper had an article proposing exactly the same thing]
Your mobile phone is an extension of yourself...

Until the introduction of printing, books were rare, and very, very expensive, maybe something like the same price as a small farm.
Only very rich people, and rich institutions, owned books.
Most books were produced by the church in monasteries.

Gutenberg brought known technologies together (just like the web did): ink, paper, wine presses, movable type.
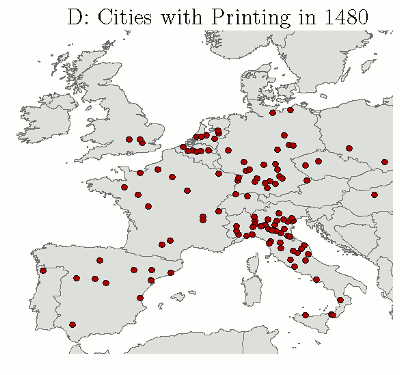
By 1500 there were 1000 printing shops in Europe, which had produced 35,000 titles and 20 million copies.
Price of books greatly diminished (First bible 300 florins, about 3 years wages for a clerk).
Suddenly, the church and state were not the sole providers of information.
Books became a new means of distribution of information.
It was a paradigm shift - new industries, bookshops, newspapers.
Many ascribe the enlightenment to the availability of books, because all of a sudden more people could share information.
But the church and state did not like losing control, and so still tried to influence information flow.
For instance Galileo (1564-1642) had to be very careful about what he wrote. He was condemned to house arrest in 1633 for the rest of his life for suggesting that the earth moved round the sun.
His books were banned until 1741.
The church finally officially admitted their error in 1992 by the way.
Not that book banning ended there... you might want to peruse the Wikipedia list of banned books.
Also, on a contemporary note, it is worth noting that the French state permanently banned the forerunner of the French satirical weekly that has been in the news this week, Charlie Hebdo, when they published satirical material about Charles de Gaulle on his death. It was that that caused them to start a new weekly called Charlie Hebdo, to get round the ban.
"At that time it was common practice for the church and the state to monitor everything that was said, written and printed. This practice is known as censorship. Anyone who dared to criticise the Church, the King and his officials was prohibited from speaking and could even go to prison. In most countries there were many officials who constantly screened everything that was said or written. [...] The enlightenment thinkers were totally opposed to censorship. They wanted the freedom to express their thoughts and ideas."
1665: first scientific journals French Journal des Sçavans and the British Philosophical Transactions.
These were actually different from modern-day scientific journals: they were created to help scientists deal with information overload: So many books were being published, that these provided abstracts, to keep scientists abreast of knowledge, and to help decide which books should be read.
From then on the number of scientific journals doubled every 15 years, right into the 20th century.
In fact around 1825, the first abstract journals appeared, to deal with the information overload of the scientific journals (there were 300 when the first abstract journal was published). The number of abstract journals also increased exponentially.
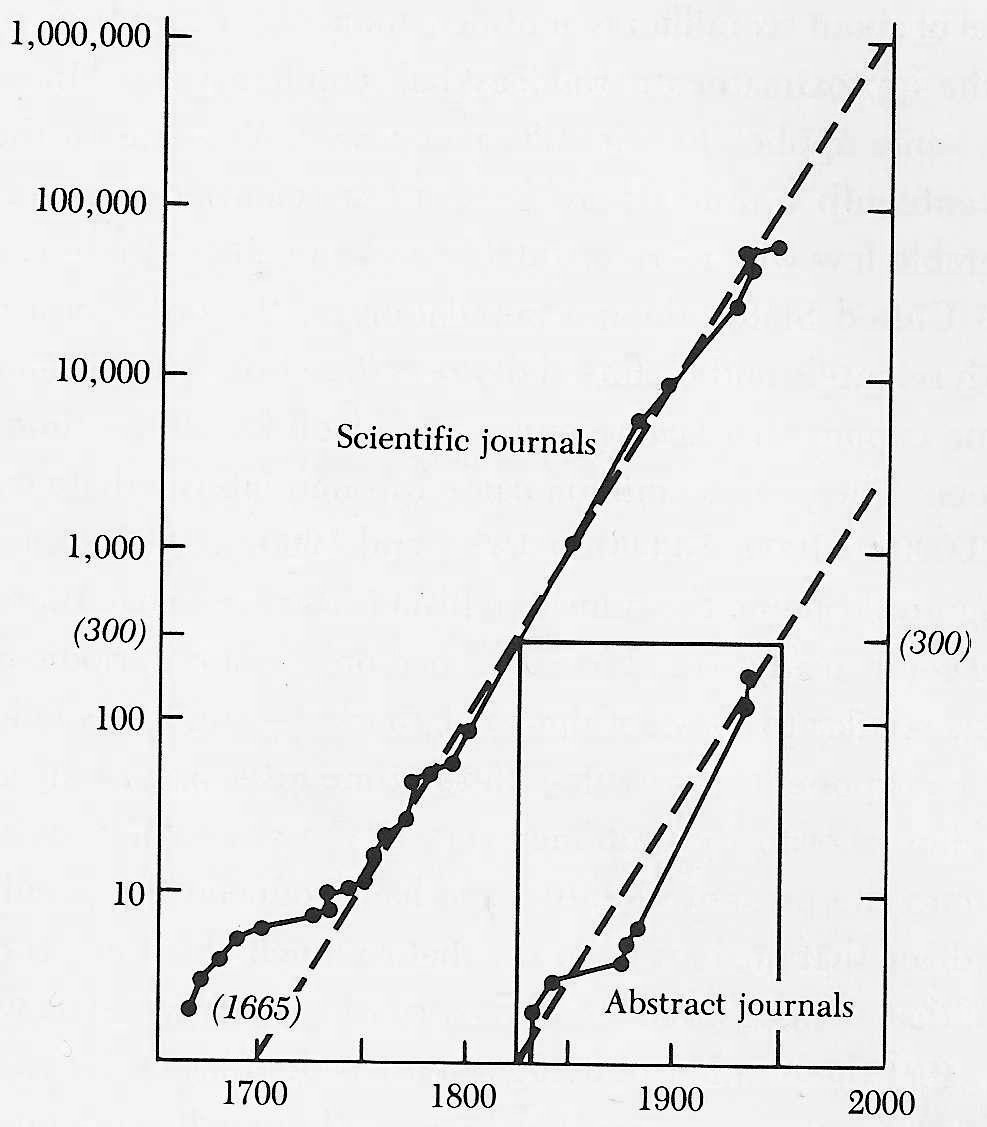
(From Little Science, Big Science ... and Beyond, by Derrek J de Solla Price)
Even as late as the 1970's if you had said "there has to come a new way of distributing information to support this growth", they would have thought you crazy, more likely expecting the growth to end: there just wouldn't be enough trees to support that many journals.
But now that we have the internet, the amount of information produced continues to increase at an exponential rate (doubling every three years according to one report, every 11 hours according to another).
According to one report, in 2013 3.5 zettabytes of data were produced.
In 1799 the prefix kilo was introduced for 1000, from the Greek word for, yep, "thousand".
It was mainly used for kilograms, and kilometres.
It wasn't until 1960 that a need was sufficiently felt for mega (million), giga (thousand million), and tera (million million). Probably for hydrogen bombs.
These were based on the greek words for "big", "giant", and "monster".
(Interestingly, we still say 1000 km, and not 1 Megametre)
These are the household prefixes we use: megapixel cameras, gigabyte memories, and terabyte disks.
I have heard youth say "That's Mega Cool" and fairly recently "That's Giga Cool!". I Haven't yet heard "That's Tera Cool!".
However, when in 1975 they wanted to upgrade again, they realised they had run out of Greek synonyms for big. So they did a sort-of clever thing.
They observed that tera is 10004, and that tera is one letter short of tetra, the Greek prefix for "four". Bingo!
So we got
Peta (from penta, five): 10005
Exa (from hexa, six): 10006
You probably won't have a petabyte disk in your home for another ten to fifteen years.
In 1991 they then altered the rule a bit, and added:
Zetta (based on hepta, seven): 10007
Yotta (based on octa, eight): 10008
That's as high as it goes for now, but my guess is that based on nona, the next one will be something like xonna, and then based on deca, something like wecca.
[By the way, last year I read the phrase "10,000 trillion gigaelectronvolts" in a news article. The author meant of course to say "10 yottaelectronvolts"].
(End of diversion)
As I was saying...
According to one report, in 2013 3.5 zettabytes of data were produced.
Which, we now know, is 3.5 × 10007 bytes (which is 3.5 × 1021 bytes).
If that were a number of seconds, it would represent 110 million million years.
Which is about 10,000 times the age of the universe.
It's a big number.
So all of a sudden, there is a new method of distributing information, much cheaper, much easier to use, accessible for next-to-no money by everyone.
And of course, the state isn't completely happy.
Up until the internet, at least in free democracies, in order to read someone's mail, listen to their phone calls, or come into their houses and read their diaries, the authorities had to get a court order that accepted the need.
Nowadays that has all changed...

Note that this (non US!) website was shut down, and its assets seized, because it had been accused of US federal crimes. It hadn't even gone to court.
"The US judge handling the case has expressed doubts about whether the case will come to court"
Megaupload was also used by journalists for - anonymously - passing information.
Lavabit was a US-based service offering privacy-guaranteed email.
In July 2013 the US federal government obtained a search warrant demanding that Lavabit give away the private SSL keys to its service affecting all Lavabit users.
However, Lavabit was forbidden from telling anyone about this search warrant.
Lavabit responded by closing down its service. It was also not in a position to tell anyone why it was closing down, though many guessed.
The US authorities had discovered that Edward Snowden used Lavabit, and wanted to read his email.
In fact, no company is allowed to tell anyone about secret subpoenas that they receive from the US government. As a result, there has been the birth of the Warrant Canary, a piece of text in annual reports that says they haven't received any subpoenas in the period. If they omit the text, then people can know that they have been served.
I had planned to say during this talk: "The state usually justify spying for reasons of paedophiles and terrorists. Watch for them saying they need more powers at the next terrorist attack".
But, today:
MI5 chief seeks new powers after Paris magazine attack
[And after the talk happened: David Cameron will on Monday tell Britain’s intelligence chiefs that he will introduce the so-called snooper’s charter and: Cameron wants to ban encryption]
Commercial interests too, are watching us.
For instance, I travelled to England via the Channel Tunnel this Christmas...

On the journey there, we had to stop the car at a booth at the entrance, and fill in a long reservation number in on a touch screen, in order to know which train we would be put on.
On the way back, we drove up to the booth, and the screen already said "Welcome, Mr. Pemberton"! They must scan and store every car's number plates.
We all know how Google and Facebook are using our information.
(And don't forget, if you use Gmail, you are giving not only your own privacy away, but also the privacy of your correspondents).
But recently I was reading the British newspaper The Guardian, and even though I hadn't logged in, it offered me an advert for computer memory for the very computer I was using at that moment.
This isn't the Guardian's doing, but the advertising network that they use to supply adverts to their site.
I guess you have a vague idea of what cookies are: 'small' or even 'tiny' pieces of information stored on your computer by sites you visit.
Sort of.

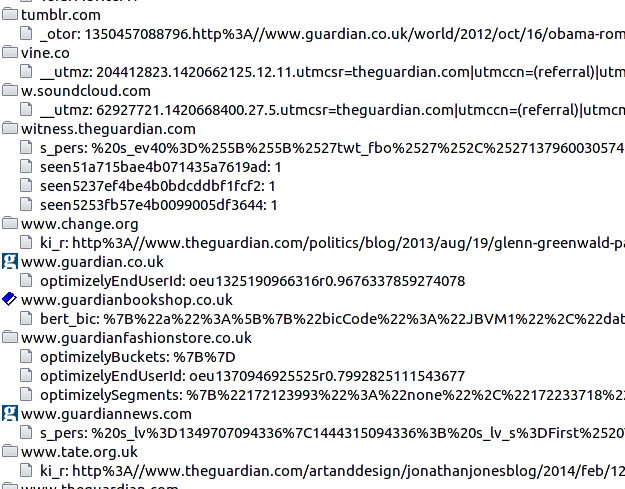
In fact the cookies file for just one of my browsers is 2Mbytes large.
With a bit of smart programming you could conclude a lot about a person from their cookies.
But in fact even cookies aren't necessary.
Some years back, my employer sent a questionnaire around to all members of staff.
They promised it was entirely anonymous, to allow people to be truthful about what they thought about working conditions.
It had been checked and OK'd by the OR.
The first two questions were "How old are you?" and "What is your nationality?"
Of course, the answers to those questions would have uniquely identified me, so I complained to the OR, and didn't fill in the questionnaire.
Because of dissatisfaction with cookies, companies are now starting to track people "statistically", using properties of your computer, behaviour, and so on.
For instance, using smart programming tricks, you can tell if someone has recently visited a set of sites (basically by looking to see if a link to that site would be displayed with blue or purple).
Of course, many of these tricks work just as well offline. The classic example is Target sending baby-supplies adverts to a teenager, when her family didn't even know she was pregnant.
Another example is Whisper, an instagram-like service for messaging, that guarantees anonymity, so you could use it for whistle-blowing, for instance.
Except it doesn't. It uses statistical techniques to track users to create a "story line". Just like my work's questionnaire, this makes it very easy to identify people.
In 2012, a non-criminal, just for fun, tried automated login attempts at random internet IP addresses. Well, he or she was really a sort-of criminal, because it's not allowed to do that. But he or she was just doing it for fun. I use this example, because most criminals don't reveal their results.
"We started scanning and quickly realized that there should be several thousand unprotected devices on the Internet."
"After completing the scan of roughly one hundred thousand IP addresses, we realized the number of insecure devices must be at least one hundred thousand."
"Starting with one device and assuming a scan speed of ten IP addresses per second, it should find the next open device within one hour. The scan rate would be doubled if we deployed a scanner to the newly found device. After doubling the scan rate in this way about 16.5 times, all unprotected devices would be found; this would take only 16.5 hours. Additionally, with one hundred thousand devices scanning at ten probes per second we would have a distributed port scanner to port scan the entire IPv4 Internet within one hour."
"The completed scan proved our assumption was true. There were in fact several hundred thousand unprotected devices on the Internet making it possible to build a super fast distributed port scanner."
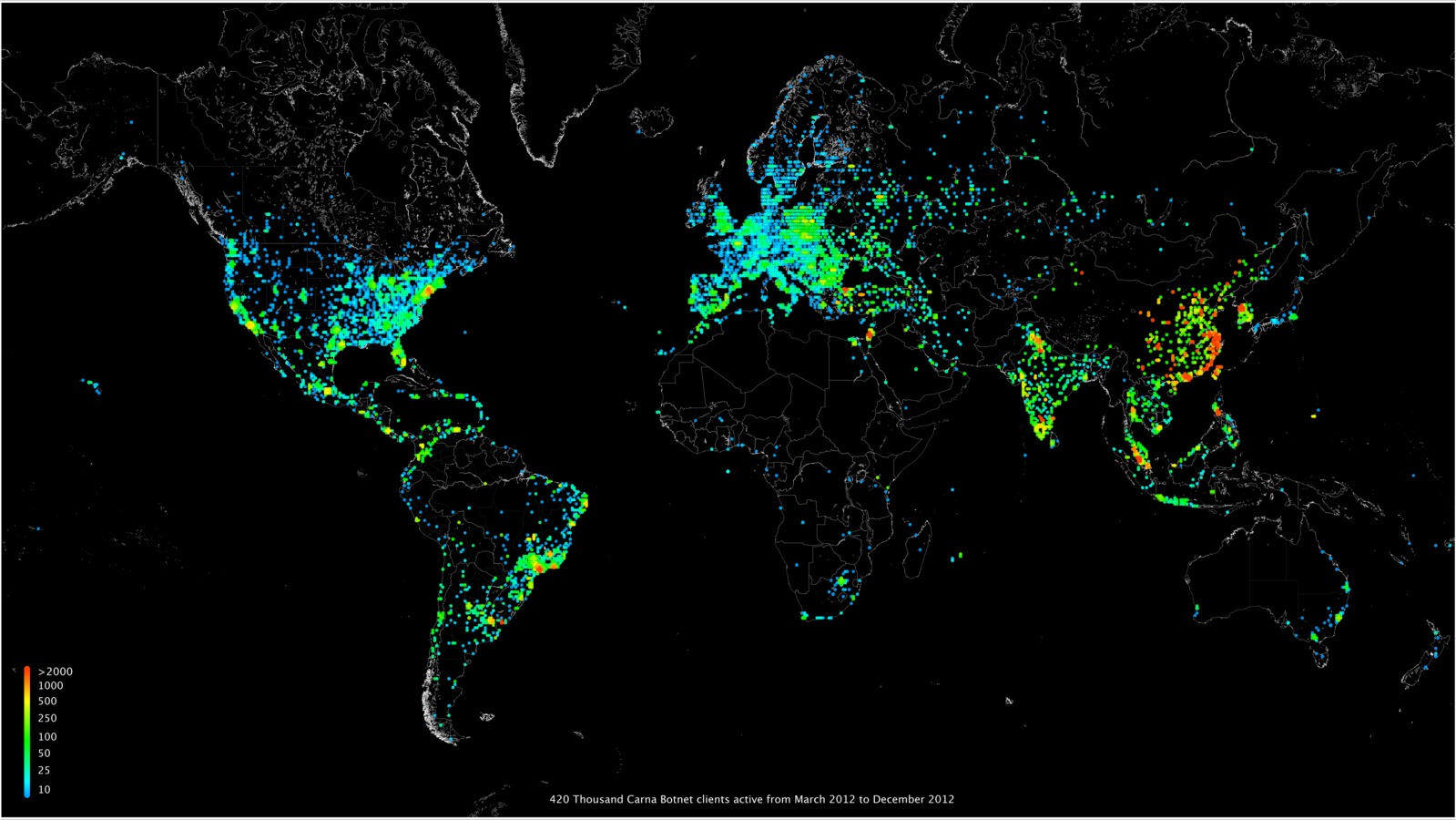
With the arrival of the $1 computer, many more household devices will have embedded computers.
Lots of things, which I don't have time to go into here, including new laws.
But one important one: end-to-end public-key cryptography.
This would make a lot of other things better too. Less spam for instance.
You know how in hotels, every room has a different lock, but there is a master key that can open all locks?
Public key cryptography works in a similar way, except the other way round:

Lock with A↷, lock with B↶, unlock with B↷, unlock with A↶
Now I can combine both things:
I am guaranteed that no one else will read it, and you are guaranteed that it really is from me. Secure messages.
This is really all that is involved.
There are extra advantages though.
For instance, I could order something from a shop by sending a secure message to them. I know that only the shop will read it, and the shop knows it really is from me.
But instead of giving them my credit card number, I give them a box with my credit card number in it, locked with my private key, and the bank's public key. So the shop doesn't know what my credit card number is, but they can send it on to the bank, and I know that only the bank can read it, and the bank knows that it really is from me.
So the only people who know what my credit card number is are me and my bank (in fact, there is no reason really to have credit card numbers at all in this system because the box can just contain the message "Please pay this shop €20" and the bank knows it is from me).
In fact the shop doesn't even need to know my address for similar reasons.
I could try to log in to a site.
I say "Hi, I'm Steven"
The site says "Oh yeah? Here's a random message. Encrypt that for me".
My browser encrypts it with my private key, the site checks it with my public key, and lets me in.
(Equivalently they could also say "Here is a message encrypted with your public key; tell me what it says"; makes no difference.)
Of course your private key is your crown jewel. If anyone gets their hands on it, you are done for.
In reality of course, there are no boxes, locks and keys: it is all done with mathematical formulas and numbers, but the principle is the same:
When you use https: to a web site, for instance with your bank, all communications are encrypted with a single key system, but which key to use is decided with a public key system first.
The internet was designed in an environment where you could trust everybody.
The infrastructure really needs to be redesigned to take away that design fault.
It is time for public-key cryptography to be an underlying part of the infrastructure.
As part of email, it would reduce spam: you would know if a mail really was from your bank.
If ISPs offered it for end-to-end connections, it would mean no one could listen in to your communications (for instance over Wifi).
If done right, it could even do away with the need for passwords.
(The slides will be online)